语法
数据结构
列表list和元组tuple
1 | l = [1, 2, 'hello', 'world'] # 列表中同时含有 int 和 string 类型的元素 |
- 列表是动态的,长度可变,可以随意的增加、删减或改变元素。列表的存储空间略大于元组,性能略逊于元组。
- 元组是静态的,长度大小固定,不可以对元素进行增加、删减或者改变操作。元组相对于列表更加轻量级,性能稍优。
- set是空的时候,进行和其他非空set取交集,永远是空
字典和集合
1 | d1 = {'name': 'jason', 'age': 20, 'gender': 'male'} |
- 字典在 Python3.7+ 是有序的数据结构,而集合是无序的,其内部的哈希表存储结构,保证了其查找、插入、删除操作的高效性。所以,字典和集合通常运用在对元素的高效查找、去重等场景。
字符串
1 | s1 = 'hello' |
- 转义字符
1 | s = 'a\nb\tc' |
常用方法
和其他数据结构,如列表、元组一样,字符串的索引同样从 0 开始,index=0 表示第一个元素(字符),[index:index+2] 则表示第 index 个元素到 index+1 个元素组成的子字符串。
字符串是不可变的(immutable)
字符串格式化
1
2print('no data available for person with id: {}, name: {}'.format(id, name)) '''最新规范'''
print('no data available for person with id: %s, name: %s' % (id, name))'''以往规范,%s 表示字符串型,%d 表示整型'''
json
- json.dumps() 这个函数,接受 基本数据类型,然后将其序列化为 string
- json.loads() 这个函数,接受一个合法字符串,然后将其反序列化为基本数据类型
条件与循环
条件
1 | # y = |x| |
循环
1 | # 列表 |
while
1 | while True: |
异常
- 当程序中存在多个 except block 时,最多只有一个 except block 会被执行。换句话说,如果多个 except 声明的异常类型都与实际相匹配,那么只有最前面的 except block 会被执行,其他则被忽略。
1 | try: |
- 无论发生什么情况,finally block 中的语句都会被执行,哪怕前面的 try 和 excep block 中使用了 return 语句。
1 | import sys |
- 自定义异常,定义并实现了初始化函数和 str 函数(直接 print 时调用):
1 | class MyInputError(Exception): |
函数
1 | def name(param1, param2, ..., paramN): |
参数
为了能让一个函数接受任意数量的位置参数,可以使用一个*参数
1
2
3
4def avg(first, *rest):
...
# Sample use
avg(1, 2)为了接受任意数量的关键字参数,使用一个以**开头的参数
1
2
3def make_element(name, value, **attrs):
...
make_element('item', 'Albatross', size='large', quantity=6)1
2
3def anyargs(*args, **kwargs):
print(args) # A tuple
print(kwargs) # A dict参数默认值不要设置 [],而是写成 None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def spam(a, b=[]): # NO! ,后面如果多次调用spam方法,则b的值会一直传递使用
...
### 函数嵌套
- 函数的嵌套能够保证内部函数的隐私。
- 合理的使用函数嵌套,能够提高程序的运行效率
```python
def f1():
print('hello')
def f2():
print('world')
f2()
f1()
# 输出
hello
world
函数变量
局部变量:只在函数内部有效。一旦函数执行完毕,局部变量就会被回收
全局变量:不能在函数内部随意改变全局变量的值,如果我们一定要在函数内部改变全局变量的值,就必须加上 global 这个声明
1
2
3
4
5
6
7
8MIN_VALUE = 1
MAX_VALUE = 10
def validation_check(value):
global MIN_VALUE
...
MIN_VALUE += 1
...
validation_check(5)
闭包
1 | def nth_power(exponent): |
1 | def counter(): |
由于闭包的存在,
count变量的状态会被保留下来,而不是每次调用counter函数都会重新初始化,这样就实现了一个持久的计数器功能。
闭包的关键特点是:一个内部函数被外部函数返回,内部函数在执行时记住了外部函数的变量。它像一个”小盒子”,封闭并记住了外部变量,即使外部函数已经执行完毕。
闭包的好处在于它可以将数据和功能打包在一起,形成一个独立的单元,可以在不同的地方重复使用,并且可以保持数据的状态。这种机制使得闭包在实现状态保持、回调函数、装饰器等方面非常有用。
这种特性在实际编程中很有用,比如实现私有变量、缓存等。当然,过度使用也会影响代码可读性。总之,理解了闭包的工作原理,就能更好地掌握这个强大的工具。
匿名函数
- lambda 是一个表达式(expression),并不是一个语句(statement)
- lambda 的主体是只有一行的简单表达式,并不能扩展成一个多行的代码块
1 | square = lambda x: x**2 |
函数式编程
所谓函数式编程,是指代码中每一块都是不可变的(immutable),都由纯函数(pure function)的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出,没有任何副作用
主要提供了这么几个函数:map()、filter() 和 reduce(),通常结合匿名函数 lambda 一起使用
类
类,一群有着相同属性和函数的对象的集合。
OOP思想四要素: 类 对象 属性 函数
类函数
成员函数
静态函数
1 | class Document(): |
构造函数
- 每个类都有构造函数,继承类在生成对象的时候,是不会自动调用父类的构造函数的,因此你必须在 init() 函数中显式调用父类的构造函数。它们的执行顺序是 子类的构造函数 -> 父类的构造函数。
抽象函数/抽象类
抽象类是一种特殊的类,它生下来就是作为父类存在的,一旦对象化就会报错。同样,抽象函数定义在抽象类之中,子类必须重写该函数才能使用。相应的抽象函数,则是使用装饰器 @abstractmethod 来表示。
抽象类就是这么一种存在,它是一种自上而下的设计风范,你只需要用少量的代码描述清楚要做的事情,定义好接口,然后就可以交给不同开发人员去开发和对接。
装饰器
所谓的装饰器,其实就是通过装饰器函数,来修改原函数的一些功能,使得原函数不需要修改。
Decorators is to modify the behavior of the function through a wrapper so we don’t have to actually modify the function.
函数装饰器
通常情况下,我们会把
*args和**kwargs,作为装饰器内部函数 wrapper() 的参数。*args和**kwargs,表示接受任意数量和类型的参数,因此装饰器就可以写成下面的形式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def my_decorator(func):
def wrapper(*args, **kwargs):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
- 装饰器可以接受原函数任意类型和数量的参数,除此之外,它还可以接受自己定义的参数。
```python
def repeat(num):
def my_decorator(func):
def wrapper(*args, **kwargs):
for i in range(num):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
return my_decorator
def greet(message):
print(message)
greet('hello world')
# 输出:
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello world
类装饰器
类装饰器主要依赖于函数
__call_(),每当你调用一个类的示例时,函数__call__()就会被执行一次。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Count:
def __init__(self, func):
self.func = func
self.num_calls = 0
def __call__(self, *args, **kwargs):
self.num_calls += 1
print('num of calls is: {}'.format(self.num_calls))
return self.func(*args, **kwargs)
def example():
print("hello world")
example()
# 输出
num of calls is: 1
hello world
example()
# 输出
num of calls is: 2
hello world
装饰器的嵌套
执行顺序从里到外
1
2
3
4
5
6
7
def func():
...
# 等同于
decorator1(decorator2(decorator3(func)))
metaclass
协程(Asyncio)
单线程+异步I/O
代操作系统对I/O操作的改进中最为重要的就是支持异步I/O,在Python语言中,单线程+异步I/O的编程模型称为协程。
有了协程的支持,就可以基于事件驱动编写高效的多任务程序。协程最大的优势就是极高的执行效率,因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销。协程的第二个优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不用加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
如果想要充分利用CPU的多核特性,最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
1 | import asyncio |
- 协程和多线程的区别,主要在于两点,一是协程为单线程;二是协程由用户决定,在哪些地方交出控制权,切换到下一个任务。
- 协程的写法更加简洁清晰,把 async / await 语法和 create_task 结合来用,对于中小级别的并发需求已经毫无压力。
- 写协程程序的时候,你的脑海中要有清晰的事件循环概念,知道程序在什么时候需要暂停、等待 I/O,什么时候需要一并执行到底。
数据隔离
- 在协程中,通常会使用局部变量或协程上下文来存储数据,每个协程拥有自己的数据空间,不会受到其他协程的影响。协程之间可以通过参数传递或全局变量等方式来进行数据交互,但是数据的修改只会影响当前协程的数据空间,不会影响其他协程的数据。
concurrency
并发通常用于 I/O 操作频繁的场景,而并行则适用于 CPU heavy 的场景。
并发
在 Python 中,并发并不是指同一时刻有多个操作(thread、task)同时进行。相反,某个特定的时刻,它只允许有一个操作发生,只不过线程 / 任务之间会互相切换,直到完成
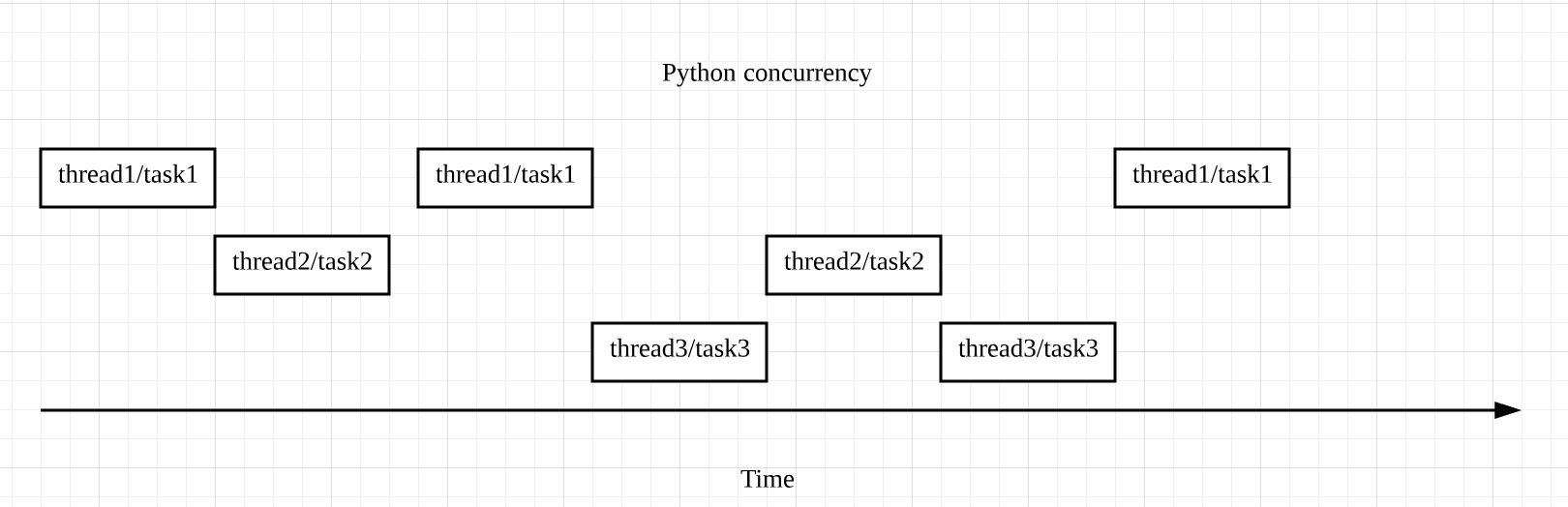
图中出现了 thread 和 task 两种切换顺序的不同方式,分别对应 Python 中并发的两种形式——threading 和 asyncio。
futures实现并发
1 | def download_all(sites): |
虽然线程的数量可以自己定义,但是线程数并不是越多越好,因为线程的创建、维护和删除也会有一定的开销。所以如果你设置的很大,反而可能会导致速度变慢。我们往往需要根据实际的需求做一些测试,来寻找最优的线程数量。
多线程每次只能有一个线程执行的原因
事实上,Python 的解释器并不是线程安全的,为了解决由此带来的 race condition 等问题,Python 便引入了全局解释器锁,也就是同一时刻,只允许一个线程执行。当然,在执行 I/O 操作时,如果一个线程被 block 了,全局解释器锁便会被释放,从而让另一个线程能够继续执行。
并行
所谓的并行,指的是同一时刻、同时发生。Python 中的 multi-processing 便是这个意思

- 并发通常应用于 I/O 操作频繁的场景,比如你要从网站上下载多个文件,I/O 操作的时间可能会比 CPU 运行处理的时间长得多。
- 而并行则更多应用于 CPU heavy 的场景,比如 MapReduce 中的并行计算,为了加快运行速度,一般会用多台机器、多个处理器来完成。
futures实现并行
1 | def download_all(sites): |
函数 ProcessPoolExecutor() 表示创建进程池,使用多个进程并行的执行程序。不过,这里我们通常省略参数 workers,因为系统会自动返回 CPU 的数量作为可以调用的进程数。
总结
1 | # 伪代码 |
multiprocessing vs threading
multiprocessing 模块可以用来创建和管理多个进程,从而实现并发任务处理。而 threading 模块则是用于多线程编程。两者在实现并发任务时有一些关键的区别:
- 进程 vs 线程:
- 多进程 (multiprocessing): 每个进程都有自己独立的内存空间和全局解释器锁 (GIL) 是完全独立的,因此多进程适合 CPU 密集型任务,因为不同的进程可以在多个 CPU 核心上并行运行。
- 多线程 (threading): 多线程共享同一个进程的内存和资源,因此管理起来可能较为复杂。Python 中的线程受到 GIL 的限制,即使在多线程中也是同一时间只允许一个线程执行 Python 字节码。多线程适合 I/O 密集型任务(如网络操作、文件读写等)。
- 全局解释器锁 (GIL):
- multiprocessing: 不受 GIL 的限制,因为每个进程都有自己的解释器实例。
- threading: 受GIL的限制,这在 CPU 密集型任务中会成为瓶颈,但在 I/O 密集型任务中影响不大。
- 内存使用:
- multiprocessing: 每个进程都有自己的内存空间,因此会使用更多的内存开销。
- threading: 共享同一内存空间,因此内存开销较小,但是需要注意线程之间的数据同步和竞争问题。
- 启动时间和开销:
- multiprocessing: 进程启动和切换的开销较大,适合长时间运行的任务。
- threading: 线程启动和切换的开销较小,适合短时间、高频率任务的并发处理。
- 数据共享和通信:
- multiprocessing: 进程间数据通信需要使用进程间通信 (IPC) 机制,如队列 (Queue)、管道 (Pipe) 或共享内存 (Shared Memory),实现起来较为复杂。
- threading: 线程间直接共享内存,因此数据共享较为方便,但需要注意同步问题,使用锁 (Lock)、条件变量 (Condition) 等机制来避免竞争条件。
在编写并发程序时,选择 multiprocessing 或 threading 取决于具体的应用场景和任务类型。如果是 CPU 密集型任务,推荐使用 multiprocessing;如果是 I/O 密集型任务,threading 可能更为合适。
multiprocessing vs concurrent.future.ProcessPoolExecutor
- 模块位置
- multiprocessing: 位于
multiprocessing模块中,是专门用于处理并行进程的模块。 - concurrent.futures.ProcessPoolExecutor: 位于
concurrent.futures模块中,是concurrent.futures提供的高层次异步并发框架的一部分,主要用于简化并发执行。
- multiprocessing: 位于
- 使用方式
- multiprocessing: 提供了相对底层的接口和灵活性,例如
Process,Queue,Pipe等。你可以直接管理进程的生命周期,手动启动和终止进程,以及处理进程间通信。 - concurrent.futures.ProcessPoolExecutor: 提供了更高级别的接口,简化了多进程的管理。使用
Executor对象来管理进程池,提交任务,获取结果更加方便和直观。
- multiprocessing: 提供了相对底层的接口和灵活性,例如
- 任务提交和结果获取
- multiprocessing: 你需要自己手动管理任务的提交和结果的汇总,通常通过队列 (Queue) 或管道 (Pipe) 来实现。
- concurrent.futures.ProcessPoolExecutor: 提供了
submit和map函数来提交任务,并且返回 Future 对象,可以方便地获取任务的执行结果。
- 异步特性
- multiprocessing: 提供了一些基础的异步特性,但主要还是同步调用,需要自行处理异步结果。
- concurrent.futures.ProcessPoolExecutor: 专门设计为异步框架,与 Python 的
asyncio更加友好,可以使用Future对象进行异步任务的管理。
GIL
Global Interpreter Lock,即全局解释器锁
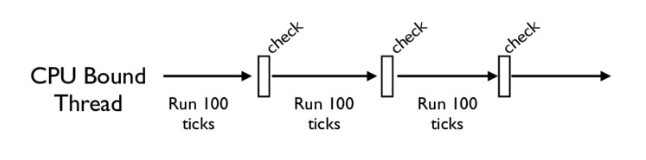
任何线程执行前必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行
python引进GIL的原因
- 一是设计者为了规避类似于内存管理这样的复杂的竞争风险问题(race condition);
- 二是因为 CPython 大量使用 C 语言库,但大部分 C 语言库都不是原生线程安全的(线程安全会降低性能和增加复杂度)
工作机制
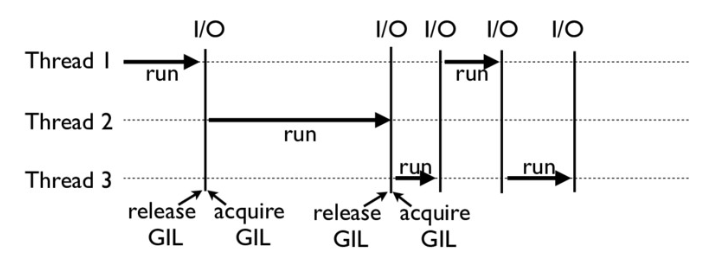
check interval
CPython 中还有另一个机制,叫做 check_interval,意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况。每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
assert
assert 语句,可以说是一个 debug 的好工具,主要用于测试一个条件是否满足。如果测试的条件满足,则什么也不做,相当于执行了 pass 语句;如果测试条件不满足,便会抛出异常 AssertionError,并返回具体的错误信息(optional)
语法
1 | assert_stmt ::= "assert" expression ["," expression] |
例如:
1 | 例子1: |
- 不要在使用 assert 时加入括号,否则无论表达式对与错,assert 检查永远不会 fail
with
在 Python 中,解决资源泄露的方式是上下文管理器(context manager)。上下文管理器,能够帮助你自动分配并且释放资源,其中最典型的应用便是 with 语句
1 | 示例一: |
基于类的上下文管理器
当我们用类来创建上下文管理器时,必须保证这个类包括方法
”__enter__()”和方法“__exit__()”。其中,方法“__enter__()”返回需要被管理的资源,方法“__exit__()”里通常会存在一些释放、清理资源的操作,比如这个例子中的关闭文件等等。
1 | class FileManager: |
- 基于生成器的上下文管理器
使用装饰器 contextlib.contextmanager,来定义自己所需的基于生成器的上下文管理器,用以支持 with 语句
1 | from contextlib import contextmanager |
ASGI
the Asynchronous Server Gateway Interface.
性能调试
cProfile
用法 tips
引用规范
from your_file import function_name, class_name定义函数时,所有非默认参数将在默认参数之前
1
2
3def my_function(arg1, arg3, arg2="default"):
# 函数实现
passpass是一个用于暂时占位或作为空占位符的关键字,它确保代码能够顺利通过语法检查而不做任何实际的操作。每个Python文件都有一个特殊的变量
__name__。当一个Python文件被直接运行时,__name__的值被设置为'__main__'。当一个Python文件被导入到另一个文件中时,__name__的值被设置为该文件的名字,所以用if __name__ == '__main__'来避开 import 时执行。比较和拷贝
'=='操作符比较对象之间的值是否相等'is'操作符,相当于比较对象之间的 ID 是否相等对于整型数字来说,以上
a is b为 True 的结论,只适用于 -5 到 256 范围内的数字
值传递、引用传递
- 变量的赋值,只是表示让变量指向了某个对象,并不表示拷贝对象给变量;而一个对象,可以被多个变量所指向。
- 可变对象(列表,字典,集合等等)的改变,会影响所有指向该对象的变量。
- 对于不可变对象(字符串,整型,元祖等等),所有指向该对象的变量的值总是一样的,也不会改变。但是通过某些操作(+= 等等)更新不可变对象的值时,会返回一个新的对象。
- 变量可以被删除,但是对象无法被删除。
容器是可迭代对象,可迭代对象调用 iter() 函数,可以得到一个迭代器。迭代器可以通过 next() 函数来得到下一个元素,从而支持遍历。
生成器是一种特殊的迭代器(注意这个逻辑关系反之不成立)。使用生成器,你可以写出来更加清晰的代码;合理使用生成器,可以降低内存占用、优化程序结构、提高程序速度。