命令
清空数据
cache -clear -c=xxxxxlostPart
1
2cache -rebalance -c=xxxx
cache -rebalance 命令不需要依赖于 cache -stop 的操作。启动或重新启动分区重平衡可以在缓存运行期间进行,不需要停止缓存。停止多个缓存表
cache -stop --caches=myCache_*
- 重新平衡多个缓存表
cache -rebalance --caches=myCache1,myCache2,myCache3
停止所有缓存表
1
2cache -stop --all
cache -start --all重新加载所有缓存表并重新平衡
cache -l -r --allcache -clear命令只是清空缓存中的数据,但是缓存仍然处于活动状态,可以继续使用;而cache -stop命令则停止了缓存,并且清空了所有数据,需要使用cache -start命令重新启动缓存,并重新加载数据。
cache -start 命令用于启动一个已经停止的缓存。如果缓存之前已经存在并被停止,使用 cache -start 命令可以重新启动该缓存,并开始加载数据。如果该缓存之前不存在,则会创建一个新的缓存并开始加载数据。
- 查看表的状态
使用 cache -state 命令查看指定缓存表的状态,包括缓存大小、分区数量、复制和备份数等信息。
设置复制和备份数量:
cache -rebalance -r
其中
设置备份数量为1,即每个分区都在一个不同的节点上保留1个备份数量
设置复制数量为2,即每个缓存表的分区都会在集群中的两个节点上复制
复制和备份都是为了提高数据可用性和可靠性,但复制是将同一份数据存储在多个节点上,而备份是将数据副本存储在集群中的不同节点上。在配置Ignite缓存表时,可以同时设置复制和备份的数量来确保数据的高可用性和可靠性。
如果有三个Ignite节点,可以按照以下建议设置缓存表的复制和备份数量:
复制因子建议设置为2,这样每个分区的数据都会在两个节点上进行备份,当一个节点故障时,可以保证数据的可靠性。
例如,使用ignitevisorcmd.sh命令可以这样设置:cache -set-replicas myCache 2
备份数量建议设置为1,这样每个分区的数据都会在一个节点上进行备份,当一个节点故障时,可以保证数据的可靠性,并且减少额外的网络开销。
例如,使用ignitevisorcmd.sh命令可以这样设置:cache -set-backups myCache 1
需要注意的是,设置复制和备份数量会增加网络和存储开销,因此需要根据具体场景进行权衡和调整。
此外,还需要根据数据大小、访问模式、节点配置等因素进行性能测试和优化。
知识点
ignite-2.7.0
- 编译ignite-core模块的时候需要使用jdk8,因为会报jdk.internal.misc.SharedSecrets找不到的错误原因:估计是在GridUnsafe.java中的miscPackage方法以及javaNioAccessObject的
Class<?> cls = Class.forName(pkgName + ".misc.SharedSecrets");出现的问题,jdk11中SharedSecrets出现的位置是jdk.internal.access.SharedSecrets
持久化
- Ignite的原生持久化会在磁盘上存储一个数据的超集,以及根据容量在内存中存储一个子集。比如,如果有100个条目,然后内存只能存储20条,那么磁盘上会存储所有的100条,然后为了提高性能在内存中缓存20条。
- 和纯内存的使用场景一样,当打开持久化时,每个独立的节点只会持久化数据的一个子集,不管是主还是备节点,都是只包括节点所属的分区的数据,总的来说,整个集群包括了完整的数据集。
- 在开发应用时可能需要修改自定义对象字段的类型。例如假设对象A的字段类型
A.range为int类型,然后决定将A.range的类型修改为long类型。之后会发现集群或应用将无法重启,因为Ignite不支持字段/列类型的更改。 - 无法变更枚举值的顺序,也无法在枚举值列表的开始或者中部添加新的常量,但是可以在列表的末尾添加新的常量。
ZooKeeper Discovery
ZooKeeper Discovery是为需要保持易扩展性和线性性能的大规模部署而设计的。然而,同时使用Ignite和ZooKeeper需要配置和管理两个分布式系统,这可能是一个挑战。因此,我们建议你只有在计划扩展到100个或1000个节点时才使用ZooKeeper Discovery。否则,最好使用TCP/IP发现。
目录结构
marshaller
$IGNITE_HOME/work/db/marshaller 类classpath信息
binary_meta
$IGNITE_HOME/work/db/binary_meta 类的元素信息
下面三个配置项是在配置文件中进行配置
storagePath
$RDX_HOME/data/ignite/persistent 持久化文件
walPath
$RDX_HOME/data/ignite/wal_store 持久化数据的元数据信息(类名、元素名、位置)
- walPath和storagePath存储的数据的关联
walArchivePath
$RDX_HOME/data/ignite/wal_archive
- 和walPath存储的数据结构一样,二者的关系
Ignite and ZooKeeper Configuration Considerations
- zookeeper中 tickTime和syncLimit参数的定义
When using ZooKeeper Discovery, you need to make sure that the configuration parameters of the ZooKeeper cluster and Ignite cluster match each other.
Consider a sample ZooKeeper configuration, as follows:
1 | # The number of milliseconds of each tick |
- 在zookeeper中 tickTime和syncLimit参数的作用
Configured this way, ZooKeeper server detects its own segmentation from the rest of the ZooKeeper cluster only after tickTime * syncLimit elapses. Until this event is detected at ZooKeeper level, all Ignite nodes connected to the segmented ZooKeeper server do not try to reconnect to the other ZooKeeper servers.
- 在ignite中 sessionTimeout参数与zookeeper的tickTime和syncLimit参数的关联
On the other hand, there is a sessionTimeout parameter on the Ignite side that defines how soon ZooKeeper closes an Ignite node’s session if the node gets disconnected from the ZooKeeper cluster. If sessionTimeout is smaller than tickTime * syncLimit , then the Ignite node is notified by the segmented ZooKeeper server too late — its session expires before it tries to reconnect to other ZooKeeper servers.
To avoid this situation, sessionTimeout should be bigger than tickTime * syncLimit.
sqlline
TIPS:
Keep in mind that, in Ignite, the concepts of a SQL table and a key-value cache are two equivalent representations of the same (internal) data structure. You can access your data using either the key-value API or SQL statements, or both.
A cache is a collection of key-value pairs that can be accessed through the key-value API. A SQL table in Ignite corresponds to the notion of tables in traditional RDBMSs with some additional constraints; for example, each SQL table must have a primary key.
A table with a primary key can be presented as a key-value cache, in which the primary key column serves as the key, and the rest of the table columns represent the fields of the object (the value).
登录
1 | IGNITE_HOME/bin/sqlline.sh --verbose=true -u jdbc:ignite:thin://ip地址/PUBLIC |
issues
BinaryObjectException: Conflicting enum values
原因
1
2
3
4
5
6
7存入ignite的数据格式
key: String , value: Map<Enum, BigDecimal>
Enum类型包含
{A,B,C}
在之后由于业务变更,需要新增新的enum项目,并添加D在A与B之间
{A,D,B,C}分析
1
由于在数据存入ignite之后,ignite会保存数据相关的schema信息,此时在enum项目之间修改item,会打乱之前的index
解决
1
2
3
4
5
6方法一:
更改enum类的名称,不再使用原有的schema信息
方法二:
enum类新增项目时,需要在最后面添加,避免打乱已有的schema索引
方法三(未验证):
删除 $IGNITE_HOME/work/binary_meta/Nodex里面的文件官方说明
- You cannot change the types of existing fields.
- You cannot change the order of enum values or add new constants at the beginning or in the middle of the list of enum’s values. You can add new constants to the end of the list though.
处理conflict enum values, 需要清除数据
需要清理 $IGNITE_HOME/work/db目录下的 binary_meta、marshaller
需要验证是否清理 storagePath、walPath、walArchivePath
gc
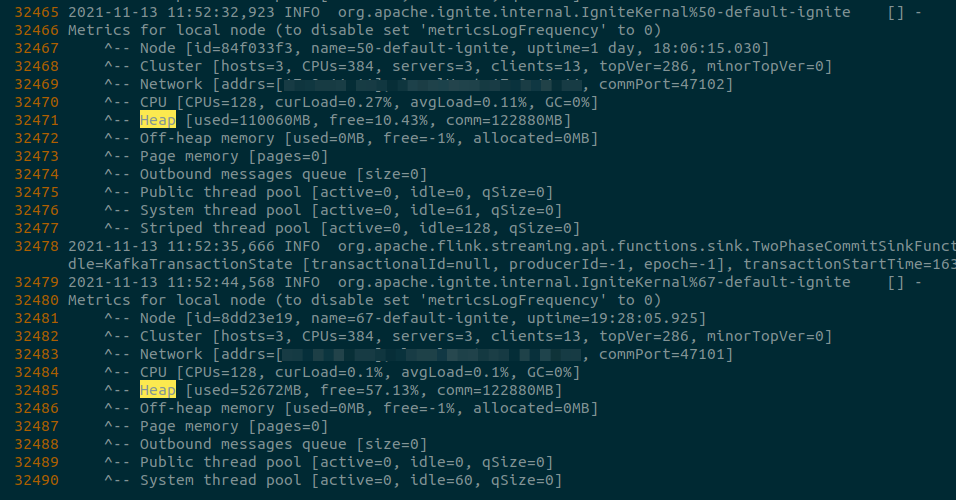
3s进行gc (110060-52672)/1024=56.04G
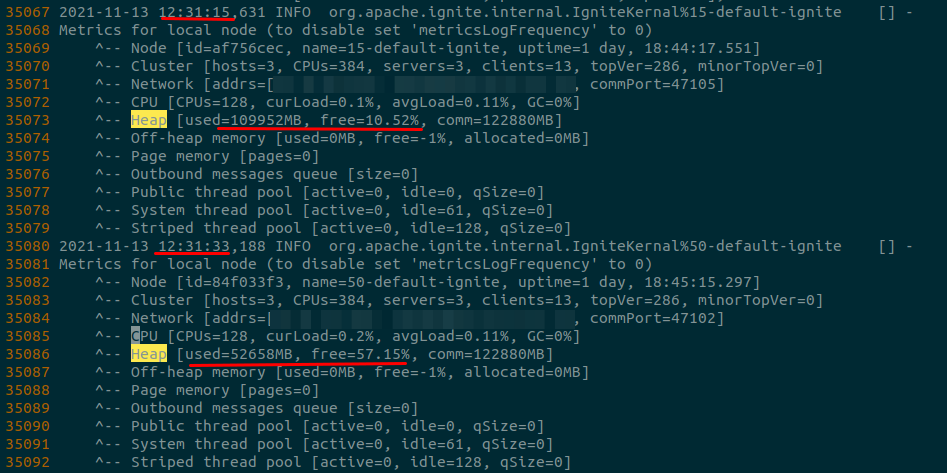
17s进行gc (109952-52658)/1024=55.95G
IgniteCacheException
1 | ERROR org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi [] - Failed to send message to remote node [node=ZookeeperClusterNode [id=1c8a032d-042e-4386-9ce8-2605c0699304, addrs=[17.9.11.11], order=1, loc=false, client=false], msg=GridIoMessage [plc=2, topic=TOPIC_CACHE, topicOrd=8, ordered=false, timeout=0, skipOnTimeout=false, msg=GridNearLockRequest [topVer=AffinityTopologyVersion [topVer=358, minorTopVer=0], miniId=1, dhtVers=GridCacheVersion[] [null], subjId=a5dbdc1d-e76e-49c2-85d7-ed7f1c7db7bd, taskNameHash=0, createTtl=-1, accessTtl=-1, flags=3, txLbl=null, filter=null, super=GridDistributedLockRequest [nodeId=a5dbdc1d-e76e-49c2-85d7-ed7f1c7db7bd, nearXidVer=GridCacheVersion [topVer=245500806, order=1638786801426, nodeOrder=336], threadId=11960694, futId=96c1bf42d71-90702925-3ef9-4c70-b7a7-4be2fb6d75ba, timeout=0, isInTx=true, isInvalidate=false, isRead=true, isolation=REPEATABLE_READ, retVals=[true], txSize=0, flags=0, keysCnt=1, super=GridDistributedBaseMessage [ver=GridCacheVersion [topVer=245500806, order=1638786801426, nodeOrder=336], committedVers=null, rolledbackVers=null, cnt=1, super=GridCacheIdMessage [cacheId=-182240380, super=GridCacheMessage [msgId=1360862, depInfo=null, lastAffChangedTopVer=AffinityTopologyVersion [topVer=336, minorTopVer=0], err=null, skipPrepare=false]]]]]]] |
- gc的策略
- ignite client的异常捕获