函数
C++ 里类的四大函数:构造函数、析构函数、拷贝构造函数、拷贝赋值函数。C++11 因为引入了右值(Rvalue)和转移(Move),又多出了两大函数:转移构造函数和转移赋值函数。
所以,在现代 C++ 里,一个类总是会有六大基本函数:三个构造、两个赋值、一个析构。
- 在 C/C++ 里,所有的函数都是全局的,没有生存周期的概念(static、名字空间的作用很弱,只是简单限制了应用范围,避免名字冲突)。而且函数也都是平级的,不能在函数里再定义函数,也就是不允许定义嵌套函数、函数套函数。
构造函数
“委托构造”(delegating constructor)
使用“委托构造”的新特性,一个构造函数直接调用另一个构造函数,把构造工作“委托”出去,既简单又高效。
1 | class DemoDelegating final |
“成员变量初始化”(In-class member initializer)
1 | class DemoInit final |
“类型别名”(Type Alias)
1 | using uint_t = unsigned int; // using别名 |
lambda
C++ 没有为 lambda 表达式引入新的关键字,并没有“lambda”这样的词汇,而是用了一个特殊的形式“[]”,术语叫“lambda 引出符”(lambda introducer)。
1 | lambda 表达式示例 |
- lambda表达式赋值必须用auto(但auto不能用在类成员初始化)
- lambda 表达式是一个闭包,能够像函数一样被调用,像变量一样被传递
- 捕获引用时必须要注意外部变量的生命周期,防止变量失效
变量捕获
[=]表示按值捕获所有外部变量,表达式内部是值的拷贝,并且不能修改[&]是按引用捕获所有外部变量,内部以引用的方式使用,可以修改
智能指针
尽量不要再使用裸指针、new 和 delete 来操作内存
unique_ptr
- 尽量不要对 unique_ptr 执行赋值操作就好了,让它“自生自灭”,完全自动化管理。
shared_ptr
- shared_ptr 支持安全共享的秘密在于内部使用了“引用计数”
- 因为 shared_ptr 具有完整的“值语义”(即可以拷贝赋值),所以,它可以在任何场合替代原始指针,而不用再担心资源回收的问题,比如用于容器存储指针、用于函数安全返回动态创建的对象,等等
容器
- 容器都具有的一个基本特性:它保存元素采用的是“值”(value)语义,也就是说,容器里存储的是元素的拷贝、副本,而不是引用。从这个基本特性可以得出一个推论,容器操作元素的很大一块成本就是值的拷贝。所以,如果元素比较大,或者非常多,那么操作时的拷贝开销就会很高,性能也就不会太好。
- 尽量为元素实现转移构造和转移赋值函数
- 依据元素的访问方式,分成顺序容器、有序容器和无序容器三大类别
顺序容器
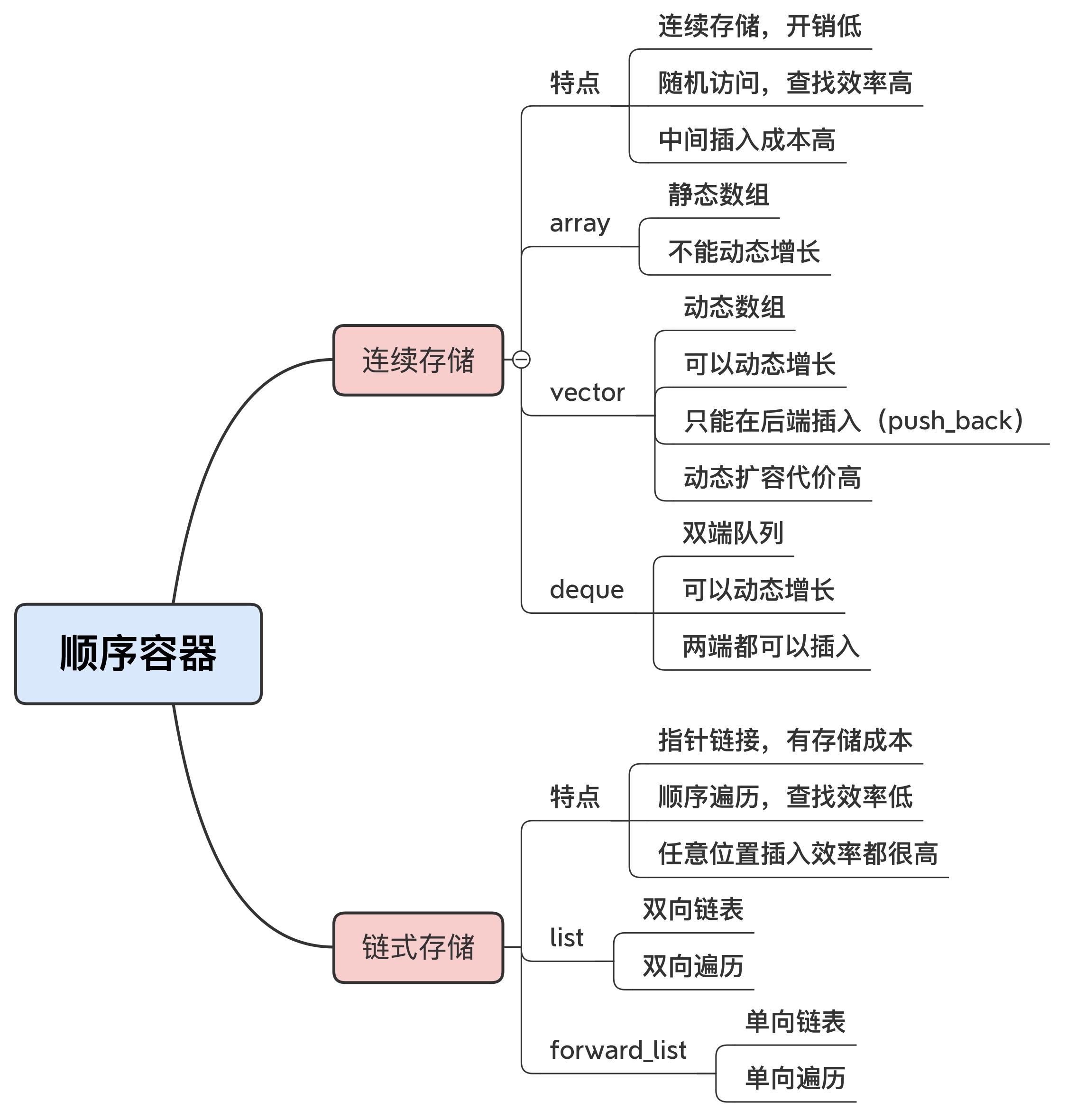
顺序容器就是数据结构里的线性表,一共有 5 种:array、vector、deque、list、forward_list,按照存储结构,这 5 种容器又可以再细分成两组。
连续存储的数组:array、vector 和 deque。
指针结构的链表:list 和 forward_list。
array和vector直接对应 C 的内置数组,内存布局与 C 完全兼容,所以是开销最低、速度最快的容器。它们两个的区别在于容量能否动态增长。array 是静态数组,大小在初始化的时候就固定了,不能再容纳更多的元素。而 vector 是动态数组,虽然初始化的时候设定了大小,但可以在后面随需增长,容纳任意数量的元素。deque也是一种可以动态增长的数组,它和vector的区别是,它可以在两端高效地插入删除元素,这也是它的名字 double-end queue 的来历,而vector则只能用 push_back 在末端追加元素。vector和deque里的元素因为是连续存储的,所以在中间的插入删除效率就很低,而list和forward_list是链表结构,插入删除操作只需要调整指针,所以在任意位置的操作都很高效。链表的缺点是查找效率低,只能沿着指针顺序访问,这方面不如
vector随机访问的效率高。list是双向链表,可以向前或者向后遍历,而forward_list,顾名思义,是单向链表,只能向前遍历,查找效率就更低了链表结构比起数组结构还有一个缺点,就是存储成本略高,因为必须要为每个元素附加一个或者两个的指针,指向链表的前后节点。
当
vector的容量到达上限的时候(capacity),它会再分配一块两倍大小的新内存,然后把旧元素拷贝或者移动过去。这个操作的成本是非常大的,所以,你在使用vector的时候最好能够“预估”容量,使用 reserve 提前分配足够的空间,减少动态扩容的拷贝代价。vector的做法太“激进”,而deque、list的的扩容策略就“保守”多了,只会按照固定的“步长”(例如 N 个字节、一个节点)去增加容量。但在短时间内插入大量数据的时候就会频繁分配内存,效果反而不如vector一次分配来得好。
有序容器
顺序容器的特点是,元素的次序是由它插入的次序而决定的,访问元素也就按照最初插入的顺序。而有序容器则不同,它的元素在插入容器后就被按照某种规则自动排序,所以是“有序”的。C++ 的有序容器使用的是树结构,通常是红黑树——有着最好查找性能的二叉树。
标准库里一共有四种有序容器:set/multiset 和 map/multimap。set 是集合,map 是关联数组(在其他语言里也叫“字典”),有 multi 前缀的容器表示可以容纳重复的 key。
无序容器
分别是 unordered_set/unordered_multiset、unordered_map/unordered_multimap。无序容器同样也是集合和关联数组,用法上与有序容器几乎是一样的,区别在于内部数据结构:它不是红黑树,而是散列表(也叫哈希表,hash table)。因为它采用散列表存储数据,元素的位置取决于计算的散列值,没有规律可言,所以就是“无序”的,你也可以把它理解为“乱序”容器。
算法
- 算法其实并不神秘,因为所有的算法本质上都是 for 或者 while,通过循环遍历来逐个处理容器里的元素。
- 追求更高层次上的抽象和封装
- 算法是专门操作容器的函数,是一种“智能 for 循环”,它的最佳搭档是 lambda 表达式
迭代器
- 算法只能通过迭代器去“间接”访问容器以及元素,算法的能力是由迭代器决定的。
- 迭代器也有很多种,比如输入迭代器、输出迭代器、双向迭代器、随机访问迭代器
并发
线程
- 在 C++ 语言里,线程就是一个能够独立运行的函数
- 任何程序一开始就有一个主线程,它从 main() 开始运行。主线程可以调用接口函数,创建出子线程。子线程会立即脱离主线程的控制流程,单独运行,但共享主线程的数据。程序创建出多个子线程,执行多个不同的函数,也就成了多线程。
- 最好的并发就是没有并发,最好的多线程就是没有线程。(简单来说,就是在大的、宏观的层面上“看得到”并发和线程,而在小的、微观的层面上“看不到”线程,减少死锁、同步等恶性问题的出现几率)
- 四个基本的工具:仅调用一次、线程局部存储、原子变量和线程对象。
仅调用一次
先声明一个 once_flag 类型的变量,然后调用专门的 call_once() 函数,以函数式编程的方式,传递这个标志和初始化函数。这样即使多个线程重入 call_once(),也只能有一个线程会成功运行初始化。
1 | static once_flag flag; // 全局的初始化标志 |
线程局部存储
thread_local 标记的变量在每个线程里都会有一个独立的副本,是“线程独占”的,所以就不会有竞争读写的问题
原子变量
原子变量禁用了拷贝构造函数,在初始化的时候不能用“=”的赋值形式,只能用圆括号或者花括号
1 | atomic_int x {0}; |
线程对象
thread
TBD
async
async() 会返回一个 future 变量,可以认为是代表了执行结果的“期货”,如果任务有返回值,就可以用成员函数 get() 获取。不过要特别注意,get() 只能调一次,再次获取结果会发生错误,抛出异常std::future_error。
如果只是想简单地在线程里启动一个异步任务,完全不关心返回值,可以调用thread的成员函数detach(),比async()会方便一点
序列化
序列化,就是把内存里“活的对象”转换成静止的字节序列,便于存储和网络传输;而反序列化则是反向操作,从静止的字节序列重新构建出内存里可用的对象。
JSON 是纯文本,容易阅读,方便编辑,适用性最广
MessagePack 是二进制,小巧高效,在开源界接受程度比较高
ProtoBuffer 是工业级的数据格式,注重安全和性能,多用在大公司的商业产品里
Avro
Thrift
网络
设计模式
如何创建对象、如何组合对象,以及如何处理对象之间的动态通信和职责分配
最常用有 5 个原则,也就是常说的SOLID
SRP,单一职责(Single ResponsibilityPrinciple)
单一职责原则,简单来说就是“不要做多余的事”,更常见的说法就是“高内聚低耦合”。在设计类的时候,要尽量缩小“粒度”,功能明确单一,不要设计出“大而全”的类。
OCP,开闭(Open Closed Principle)
单一职责原则,简单来说就是“不要做多余的事”,更常见的说法就是“高内聚低耦合”。在设计类的时候,要尽量缩小“粒度”,功能明确单一,不要设计出“大而全”的类。
LSP,里氏替换(Liskov Substitution Principle)
子类必须能够完全替代父类
ISP,接口隔离(Interface-Segregation Principle)
侧重点是对外的接口而不是内部的功能,目标是尽量简化、归并给外界调用的接口,避免写出大而不当的“面条类”
DIP,依赖反转,有的时候也叫依赖倒置(Dependency Inversion Principle)
上层要避免依赖下层的实现细节,下层要反过来依赖上层的抽象定义,说白了,大概就是“解耦”
| 创建型模式 | 结构型模式 | 行为模式 | |
|---|---|---|---|
| 特点 | 隔离对象的生产和使用 | 隔离客户代码与原对象的接口 | 隔离程序里稳定的主逻辑与动态变化的部分 |
| 简单(常用) | 单件、工厂 | 适配器、外观、代理 | 职责链、命令、策略 |
| 普通(常用) | 生成器、原型 | 桥接、装饰 | 迭代器、观察者、状态、模板方法、访问者 |
| 困难(不常用) | 组成、享元 | 解释器、备忘录、中介者 |
其他
C++ 里也是有垃圾回收的,不过不是 Java、Go 那种严格意义上的垃圾回收,而是广义上的垃圾回收,这就是构造 / 析构函数和
RAII惯用法(Resource Acquisition Is Initialization)noexcept专门用来修饰函数,告诉编译器:这个函数不会抛出异常。编译器看到noexcept,就得到了一个“保证”,就可以对函数做优化,不去加那些栈展开的额外代码,消除异常处理的成本。
reference
- <<罗剑锋的C++实战笔记>>