Yet Another Resource Negotiator
YARN 看做一个云操作系统,它负责为应用程序启 动 ApplicationMaster(相当于主线程),然后再由 ApplicationMaster 负责数据切分、任务分配、 启动和监控等工作,而由 ApplicationMaster 启动的各个 Task(相当于子线程)仅负责自己的计 算任务。当所有任务计算完成后,ApplicationMaster 认为应用程序运行完成,然后退出。
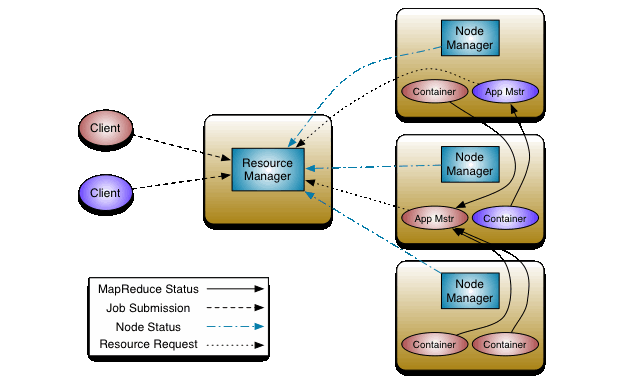
概念
contrainer
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。
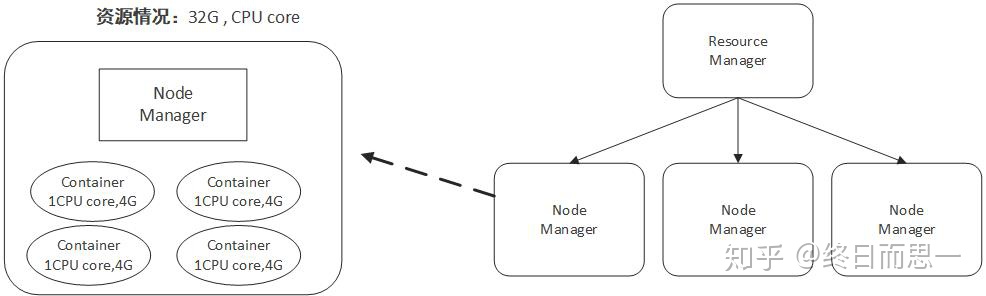
Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。
- 容器由 NodeManager 启动和管理,并被它所监控。
- 容器被 ResourceManager 进行调度。
ResourceManager
负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
ApplicationMaster
每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
ps: 大数据分布式计算的思想,大数据难以移动(海量数据移动成本太大,时间太长),那就把容易移动的应用程序发布到各个节点进行计算。
NodeManager
NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
命令
submit application to yarn
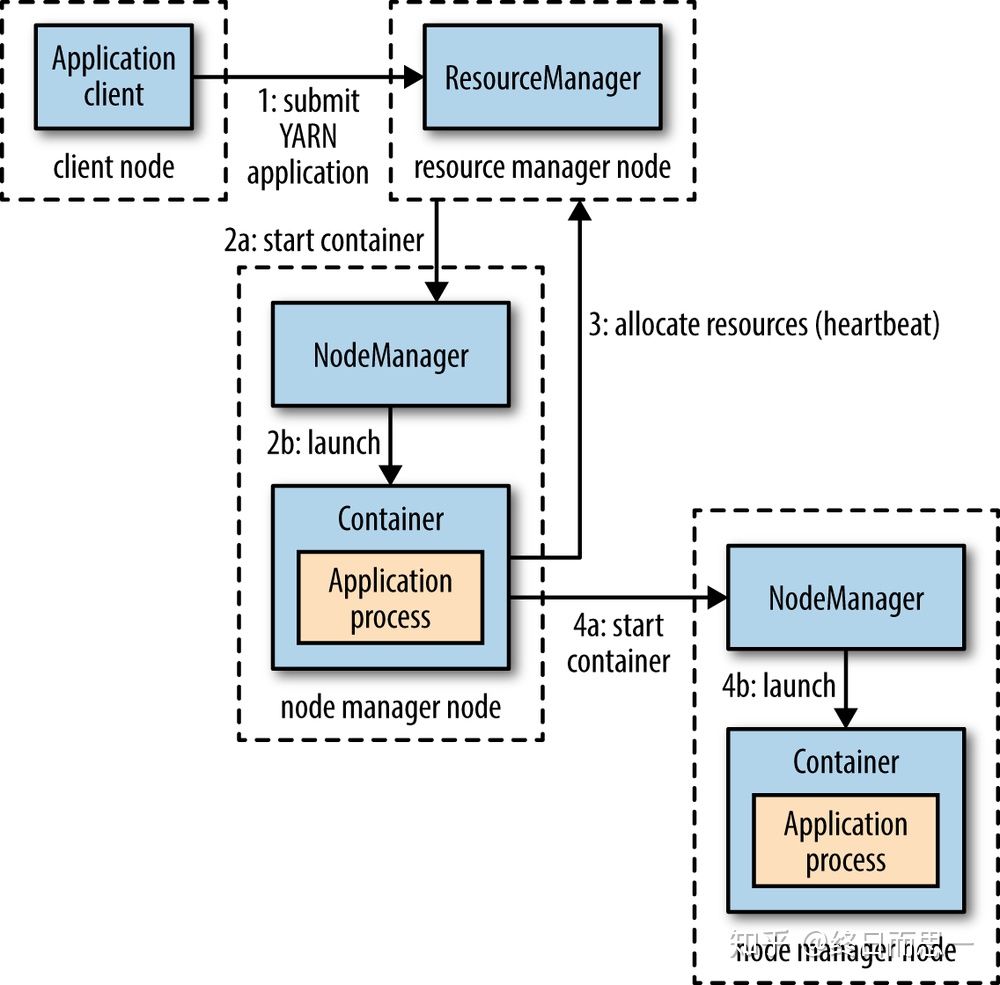
- Client 向 Yarn 提交 Application,这里我们假设是一个 MapReduce 作业。
- ResourceManager 向 NodeManager 通信,为该 Application 分配第一个容器。并在这个容器中运行这个应用程序对应的 ApplicationMaster。
- ApplicationMaster 启动以后,对 作业(也就是 Application) 进行拆分,拆分 task 出来,这些 task 可以运行在一个或多个容器中。然后向 ResourceManager 申请要运行程序的容器,并定时向 ResourceManager 发送心跳。
- 申请到容器后,ApplicationMaster 会去和容器对应的 NodeManager 通信,而后将作业分发到对应的 NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是 Map 任务,也可能是 Reduce 任务。
- 容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源。
停止应用
yarn application -kill appID
参数配置
每个job提交到yarn上执行时,都会分配Container容器去运行,而这个容器需要资源才能运行,这个资源就是Cpu和内存。
CPU资源调度
目前的CPU被Yarn划分为虚拟CPU,这是yarn自己引入的概念,因为每个服务器的Cpu计算能力不一样,有的机器可能是 其他机器的计算能力的2倍,然后可以通过多配置几个虚拟内存弥补差异。在yarn中,cpu的相关配置如下。
yarn.nodemanager.resource.cpu-vcores
表示该节点服务器上yarn可以使用的虚拟的CPU个数,默认是8,推荐配置与核心个数相同,如果节点CPU的核心个数不足8个,需要调小这个值,yarn不会智能的去检测物理核数。如果机器性能较好,可以配置为物理核数的2倍。
yarn.scheduler.minimum-allocation-vcores
表示单个任务最小可以申请的虚拟核心数,默认为1
yarn.sheduler.maximum-allocation-vcores
表示单个任务最大可以申请的虚拟核数,默认为4;如果申请资源时,超过这个配置,会抛出 InvalidResourceRequestException
Memory资源调度
yarn一般允许用户配置每个节点上可用的物理资源,可用指的是将机器上内存减去hdfs的,hbase的等等剩下的可用的内存。
yarn.nodemanager.resource.memory-mb
设置该节点上yarn可使用的内存,默认为8G,如果节点内存不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个值式yarn的可用内存资源。
yarn.scheduler.minmum-allocation-mb
单个任务最小申请物理内存量,默认是1024M,根据自己业务设定
yarn.scheduler.maximum-allocation-mb
单个任务最大可以申请的物理内存量,默认为8291M
二、如果设置这几个参数
如果一个服务器是32核,虚拟后为64核,128G内存,我们该如何设置上面的6个参数呢?即如何做到资源最大化利用
生产上我们一般要预留15-20%的内存,那么可用内存就是128*0.8=102.4G,去除其他组件的使用,我们设置成90G就可以了。
1、yarn.sheduler.maximum-allocation-vcores
1.
一般就设置成4个,cloudera公司做过性能测试,如果CPU大于等于5之后,CPU的利用率反而不是很好。这个参数可以根据生成服务器决定,比如公司服务器很富裕,那就直接设置成1:1;设置成32,如果不是很富裕,可以直接设置成1:2。我们以1:2来计算。
2、yarn.scheduler.minimum-allocation-vcores
1.
如果设置vcoure = 1,那么最大可以跑64/1=64个container,如果设置成这样,最小container是64/4=16个。
3、yarn.scheduler.minmum-allocation-mb
如果设置成2G,那么90/2=45最多可以跑45个container,如果设置成4G,那么最多可以跑24个;vcore有些浪费。
4、yarn.scheduler.maximum-allocation-mb
这个要根据自己公司的业务设定,如果有大任务,需要5-6G内存,那就设置为8G,那么最大可以跑11个container。
TIPS
配置指定用户启停
start-yarn.sh和stop-yarn.sh添加如下配置
1 | YARN_RESOURCEMANAGER_USER=xxx |
ps: 如果某个节点nodemanager没有拉起,需要执行./yarn --daemon start nodemanager
在资源够用的情况,无法发布新的应用
修改capacity-scheduler.xml
1
2
3
4
5
6
7
8
9
10<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<!--<value>0.1</value>-->
<value>0.8</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
reference: