Change Data Capture(变更数据获取)
核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
应用场景
- 数据同步,用于备份,容灾;
- 数据分发,一个数据源分发给多个下游;
- 数据采集(E),面向数据仓库/数据湖的 ETL 数据集成。
分类
主要分为基于查询和基于 Binlog 两种方式
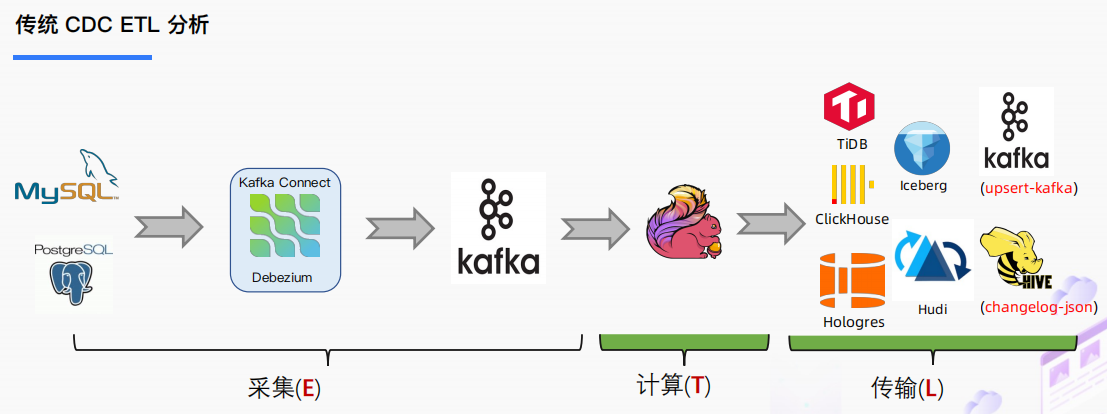
传统 CDC ETL
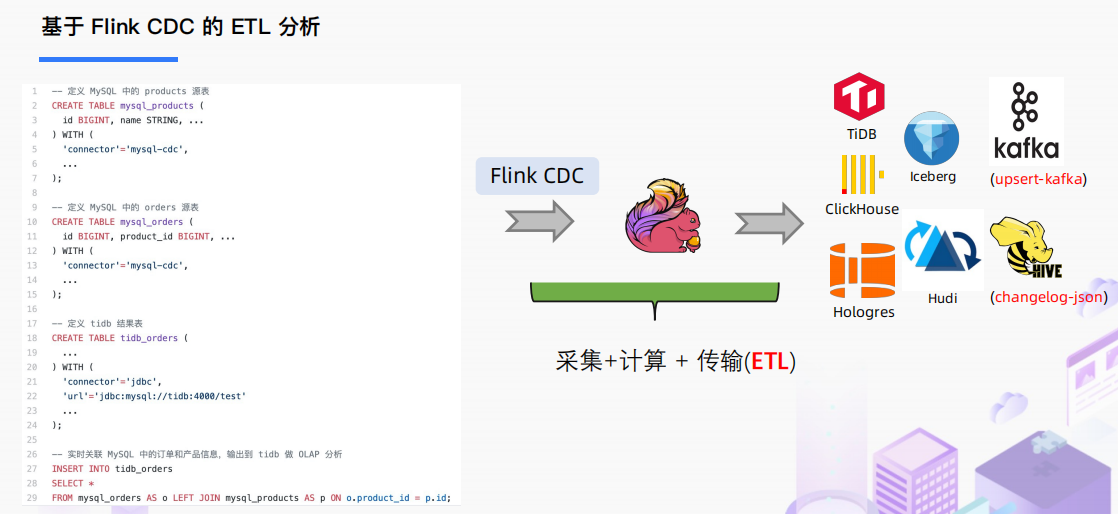
基于 Flink CDC 的 ETL 分析
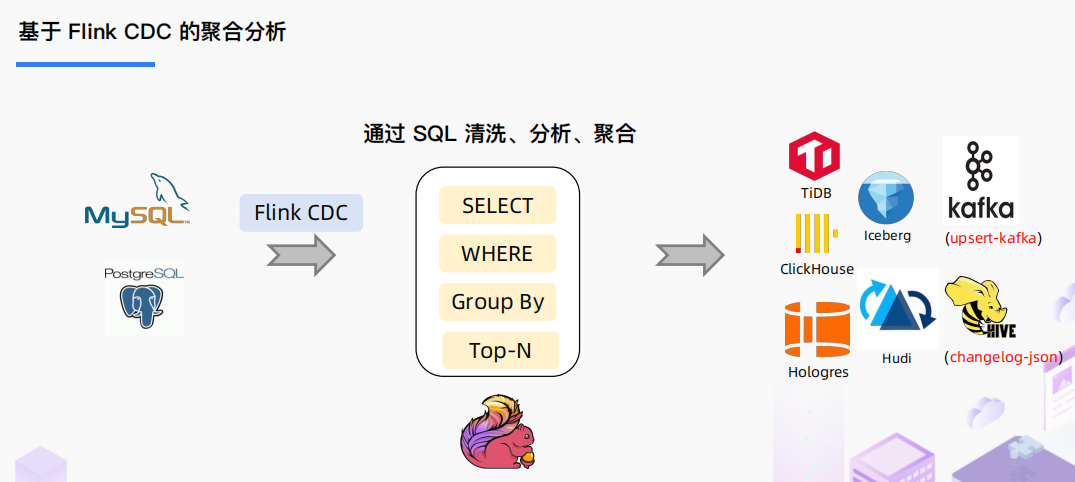
基于 Flink CDC 的聚合分析
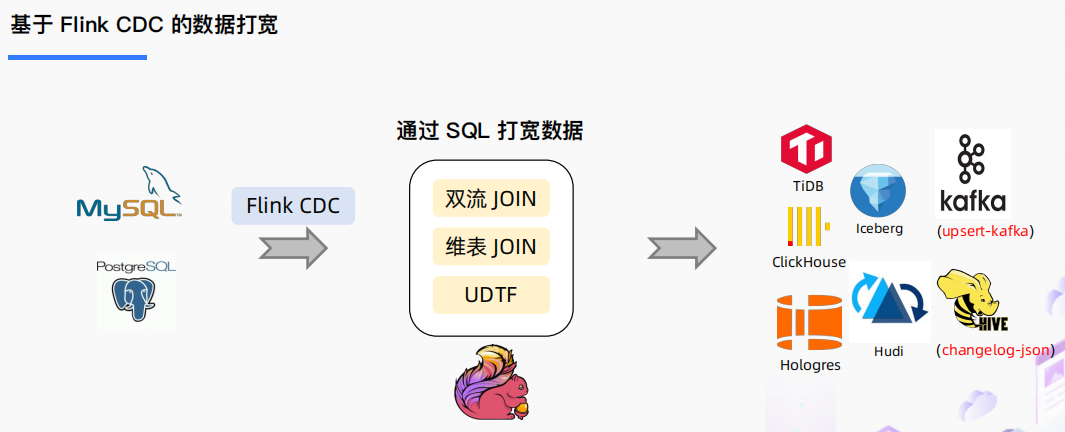
基于 Flink CDC 的数据打宽
性能点
大数据领域的 4 类场景:
B batch 离线计算
A Analytical 交互式分析
S Servering 高并发的在线服务
T Transaction 事务隔离机制
离线计算通常在计算层,所以应该重点考虑 A、S 和 T
考虑点
保证端到端的数据一致性,包括维度一致性以及全流程数据一致性;
实时流处理过程中数据到达顺序无法预知时,如何保证双流 join 时数据能及时关联同时不造成数据堵塞;
Oracle
1
21.Oracle 是第三方厂商维护的,不允许对线上系统有过多的侵入,容易造成监听故障甚至系统瘫痪,
2.归档日志是在开启那一刻起才开始生成的,之前的存量数据难以进入 kafka,但是后来实时数据又必须依赖前面的计算结果
实时数仓方案
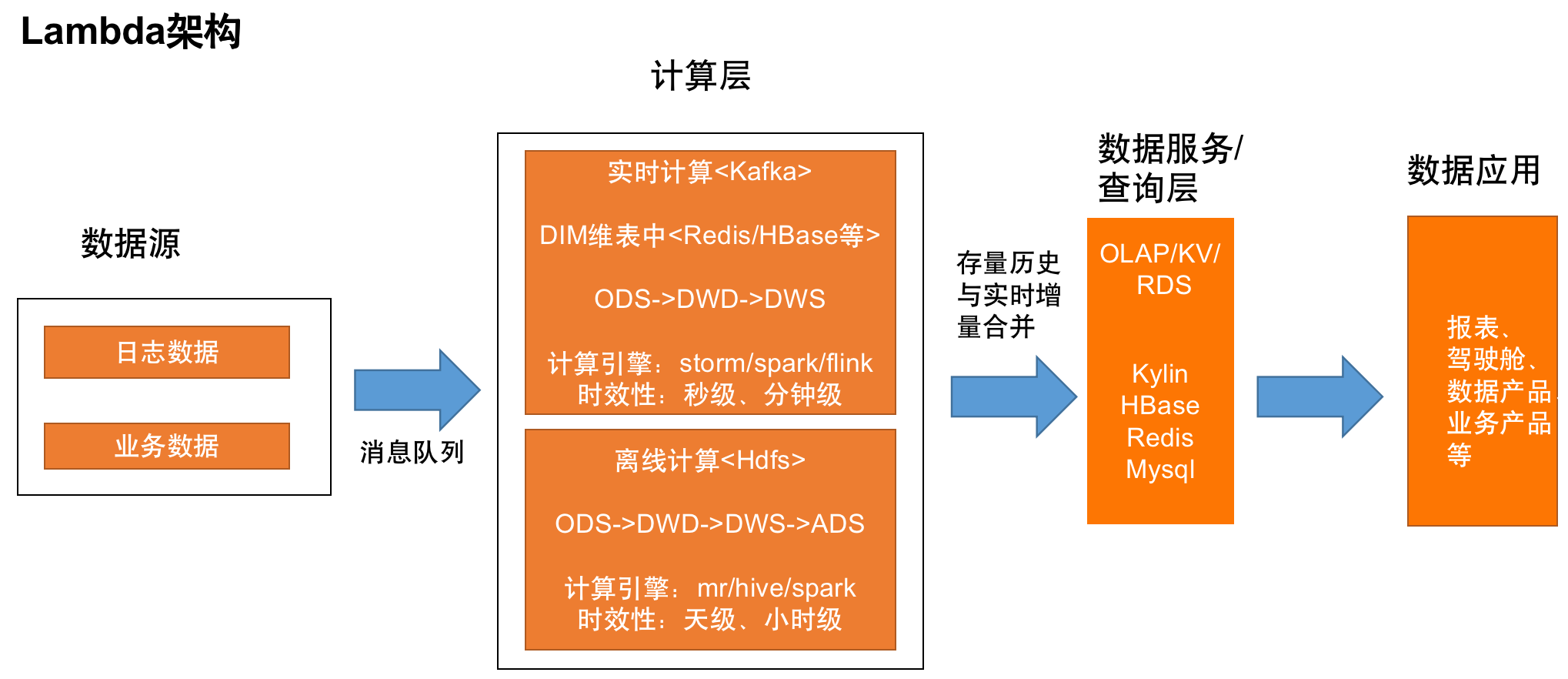
Lambda 架构
目前主流的一套实时数仓架构,存在离线和实时两条链路。实时部分以消息队列的方式实时增量消费,一般以 Flink+Kafka 的组合实现,维度表存在关系型数据库或者 HBase;离线部分一般采用 T+1 周期调度分析历史存量数据,每天凌晨产出,更新覆盖前一天的结果数据,计算引擎通常会选择 Hive 或者 Spark。
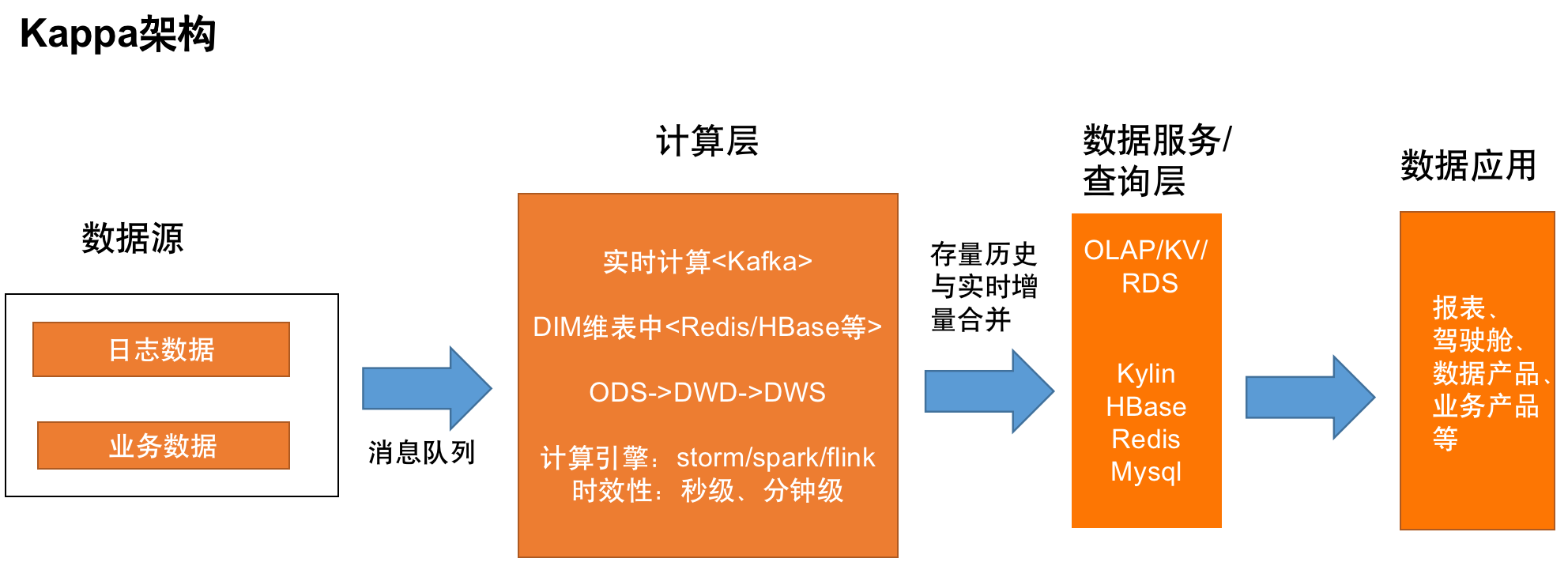
Kappa 架构
相较于 Lambda 架构,它移除了离线生产链路,思路是通过传递任意想要的 offset(偏移量)来达到重新消费处理历史数据的目的。优点是架构相对简化,数据来源单一,共用一套代码,开发效率高;缺点是必须要求消息队列中保存了存量数据,而且主要业务逻辑在计算层,比较消耗内存资源。
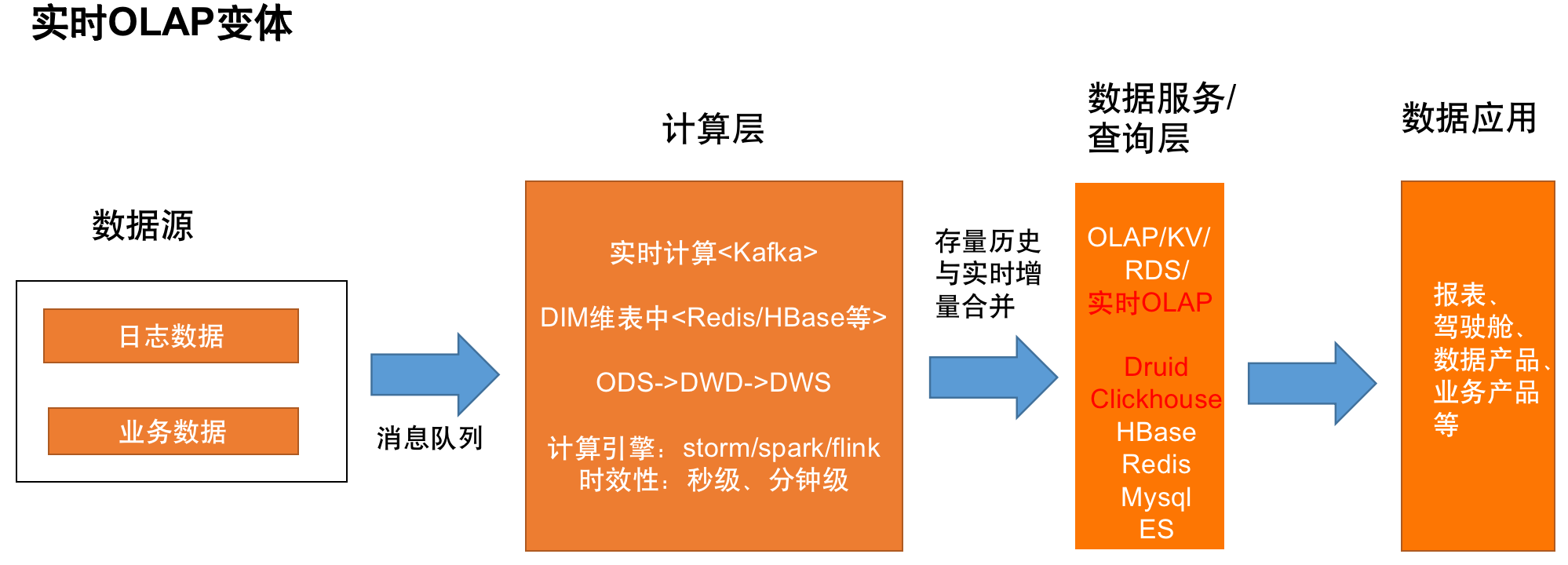
OLAP 变体架构
是 Kappa 架构的进一步演化,它的思路是将聚合分析计算由 OLAP 引擎承担,减轻实时计算部分的聚合处理压力。优点是自由度高,可以满足数据分析师的实时自助分析需求,减轻了计算引擎的处理压力;缺点是必须要求消息队列中保存存量数据,且因为是将计算部分的压力转移到了查询层,对查询引擎的吞吐和实时摄入性能要求较高。
数据湖架构
存储、计算和查询,分别由三个独立产品负责,分别是数据湖、Flink 和 Clickhouse。数仓分层存储和维度表管理均由数据湖承担,Flink SQL 负责批流任务的 SQL 化协同开发,Clickhouse 实现变体的事务机制,为用户提供离线分析和交互查询。CDC 到消息队列这一链路将来是完全可以去掉的,只需要 Flink CDC 家族中再添加 Oracle CDC 一员。未来,实时数仓架构将得到极致的简化并且性能有质的提升。
